AI Agentic UX - Seamlessly Blending Conversation and Results

2025-01-22
AI Agentic UX - Seamlessly Blending Conversation and Results
Lessons learned from exploring the concept with a POC to build a real-time AI agentic assistant.
TL;DR: Smarter Voice Assistants with Asynchronous Multi-Agent Systems
Voice assistants often freeze or simplify tasks when handling complex queries. This proof-of-concept explores an architecture that separates the real-time conversational frontend from a multi-agent, asynchronous backend, enabling uninterrupted user interaction while tasks execute in parallel.
Introduction
Voice assistants traditionally struggle when tasks get complex: either they stall the conversation until a result is ready or they simplify their functionality to keep responses snappy. As Large Language Models (LLMs) become more capable and can handle diverse tools and knowledge bases, we have an opportunity to rethink that paradigm.
This post explores an approach that separates the conversational frontend from a multi-agent, asynchronous backend. The result? A voice assistant that can carry on chatting, explain its architecture using retrieval-augmented generation (RAG), and integrate new capabilities over time — all without forcing the user to wait in awkward silence.
We’ll discuss what worked, what didn’t, and how this proof-of-concept points toward more scalable, contextually aware voice-driven systems. While the architecture demonstrated its feasibility, it also highlighted challenges such as non-deterministic agent coordination and the need for more structured, event-driven integrations. We hope this sparks a community dialogue on advancing beyond the current limits of voice assistants.
Why a More Flexible Voice Assistant?
Current voice assistants often rely on straightforward request-response cycles. If a query takes time—like fetching metrics, running a web search, or updating a homepage’s main article—the assistant either makes the user wait or returns partial/incomplete answers.
By decoupling the conversation from the execution pipeline, we allow the user to keep talking. Meanwhile, asynchronous backend agents handle complex tasks in parallel. Selective RAG integration ensures the assistant can also explain its own workings (like what the backend architecture looks like or why it made a certain decision) without halting the main conversation flow.
Architecture Overview
Frontend (AI Assistant):
- Handles user input (voice or text) in real time using advanced LLMs (e.g., Google Gemini).
- Integrates RAG only when the user explicitly asks for internal explanations or process insights. This ensures that expensive retrieval operations don’t block the main conversation.
- Uses asynchronous event loops (
asyncio) to continuously listen for backend updates, allowing the dialogue to continue as tasks complete in the background.
Backend (Multi-Agent System):
- A “supervisor” node orchestrates multiple specialized agents (e.g., an editor agent to update features, a researcher agent to run queries, an analyst agent to fetch performance metrics).
- Agents read from and write to logs, enabling loose coupling. This avoids hard-coded integrations but can lead to emergent, less predictable behavior.
- Delegation sometimes results in roundabout agent “conversations” that don’t always converge quickly to the desired outcome. Further refinement is needed to ensure determinism and reliability.
Architecture and Research Questions
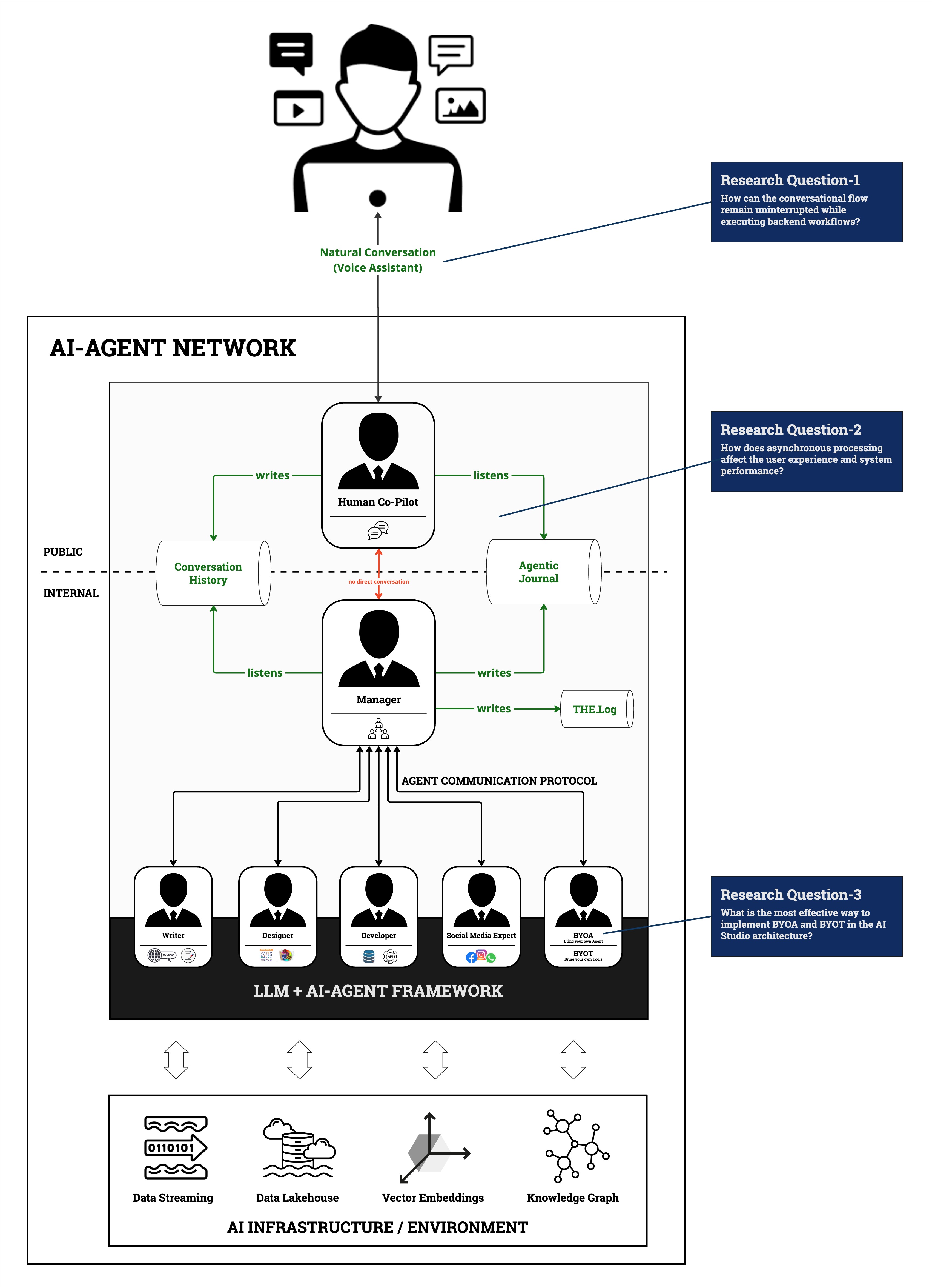
For this post, we will try to answer the other two questions:
- How can the conversational flow remain uninterrupted while executing backend workflows?
- How does asynchronous processing affect the user experience and system performance?
Under the Hood: Key Components & Code Examples
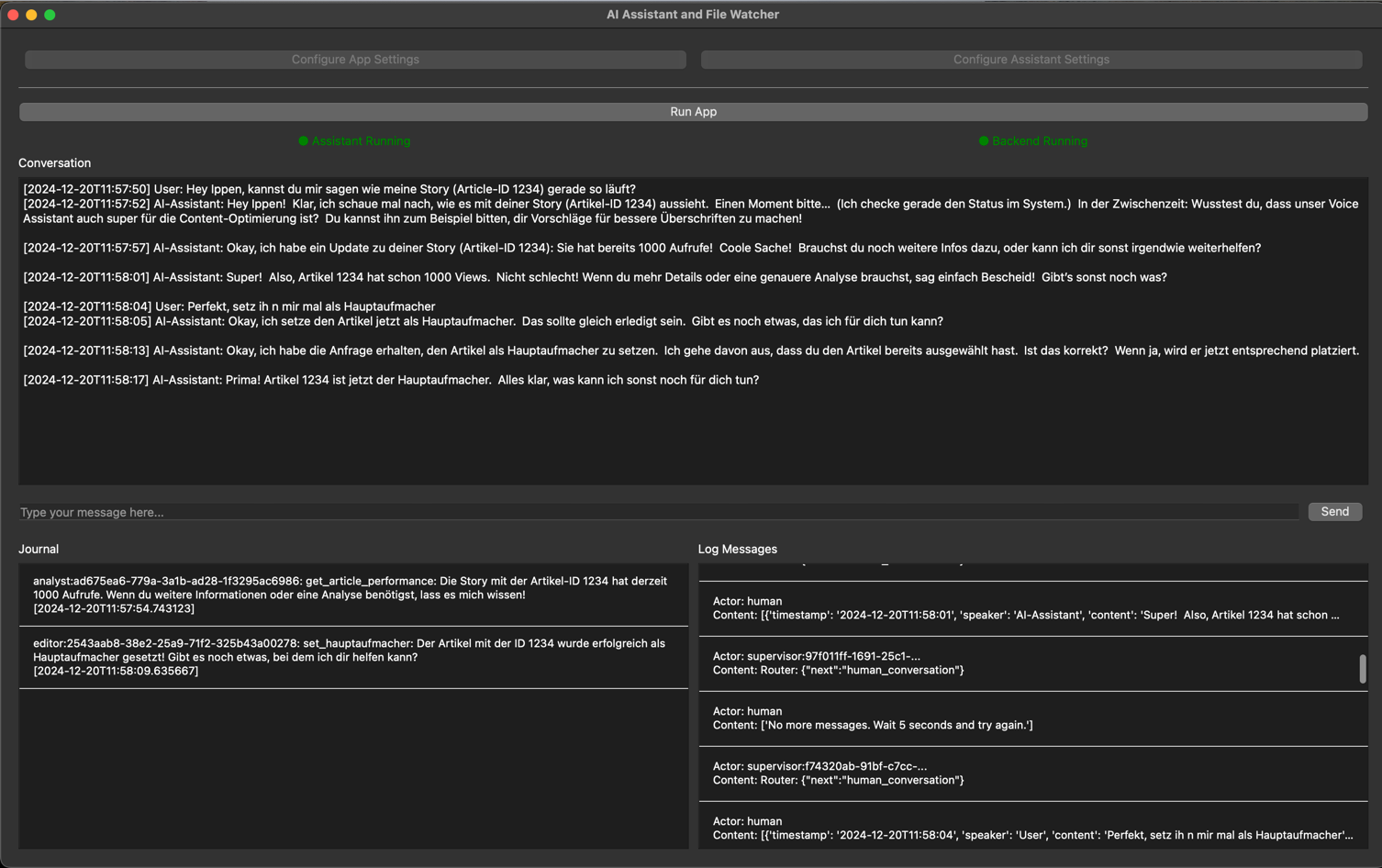
Asynchronous Conversation Flow
The frontend continually handles user queries and checks logs for backend updates. Even if the backend is processing a complex task, the assistant remains responsive:
await asyncio.gather(
self.conversation_with_user_input(), # (voice)-chat interface with the user
self.the_journal_listener(), # backend-process-output
)
Selective RAG Integration
RAG is invoked only when needed—say, if the user asks “How does the backend architecture work?” This ensures that complex retrieval tasks don’t bog down normal Q&A:
if self.assistant_settings.enable_rag:
rag_context = self.rag.get_rag_context_for_query(query=message, num_docs=3)
prompt = f"Context:\n{rag_context}\n\nQuestion: {message}\nAnswer:"
else:
prompt = message
Multi-Agent Backend Delegation
A StateGraph defines how the supervisor chooses the next agent. While flexible, this approach can sometimes cause longer-than-expected agent-to-agent exchanges:
builder.add_edge(START, "supervisor")
builder.add_node("supervisor", supervisor_node)
builder.add_node("editor", nodes["editor"])
builder.add_node("researcher", nodes["researcher"])
builder.add_node("analyst", nodes["analyst"])
builder.add_conditional_edges("supervisor", lambda state: state["next"])
Discussion: Challenges, Trade-Offs, and Next Steps
Non-Deterministic Agent Coordination
A key lesson is that while modularity and flexibility are attractive, they can lead to non-deterministic behavior. In our setup, the “supervisor” uses heuristics and LLM-driven reasoning to pick the next agent. Sometimes this results in agents debating how to proceed, prolonging resolution times.
Easy Win: Introduce clearer, more explicit intent representations and event triggers. For example, define strict conditions or “contract tests” that ensure an agent only reacts to certain triggers. Improving prompt engineering and adding explicit workflows (e.g., using a lightweight DSL or BPMN-like structure) can help.
Harder Challenge: Achieving consistently deterministic behavior at scale, especially as the number of agents and tools grows. This may require more sophisticated orchestration frameworks, stable APIs, or hierarchical supervisors that break down tasks into clearer sub-goals.
Ensuring Scalability and Low Latency
While file-based logs and polling were simple to implement, they introduce latency and complexity at scale. Modern voice assistants might need to handle thousands of parallel tasks. Latency-sensitive applications can’t afford frequent polling or lengthy handoffs.
Easy Win: Swap file-based communication for event-driven middleware—such as message queues (RabbitMQ, Kafka) or streaming databases. This would reduce latency and improve responsiveness almost immediately.
Harder Challenge: Designing a fully reactive system where agents subscribe to event streams and respond in near real-time. Ensuring that adding a new agent doesn’t require major architectural changes is trickier. It may demand establishing conventions for message schemas, lifecycle management, and failure handling.
Retrieving Context Without Blocking
RAG provides richer, more context-aware answers. The biggest benefit is giving users insights into the “why” and “how” of system behavior. However, doing so on every query would slow things down.
Easy Win: Maintain a cache of frequently asked questions about system architecture. For less common questions, fetch on-demand. Introduce resource budgeting—e.g., limit retrieval frequency or complexity.
Harder Challenge: Dynamically prioritize retrieval requests based on user engagement signals or conversation context. For instance, if the user repeatedly asks for complex internal details, how can we prefetch information without overloading the system?
Benchmarking & Best Practices
This prototype was a proof-of-concept. The next step is rigorous benchmarking: measure latency, throughput, error rates, and user satisfaction. Understanding these metrics allows us to iterate intelligently.
Adoption Tips for Practitioners:
- Start small. Introduce asynchronous processes and a single agent to handle a specific workflow.
- Use simple message passing first, then evolve to event-driven architectures as complexity grows.
- Invest in logging and observability (e.g., Prometheus/Grafana dashboards) to understand agent interactions at scale.
- Consider standardizing on an agent interface (e.g., OpenAI Function Calling style or LangChain’s Tool interface) to keep integration consistent.
Future Work: Toward a State-of-the-Art Ecosystem
The research aligns with current developments in LLM orchestration frameworks (e.g., LangChain, Haystack, OpenAI’s Function Calling APIs) and vector databases (e.g., Pinecone, Weaviate) that can serve as scalable backends for RAG. We’re just scratching the surface of what’s possible.

Planned Improvements:
- Integrate event streams for near-instant updates.
- Experiment with hierarchical agent structures (a “manager” agent that sets goals, lower-level agents that solve subproblems).
- Enhance RAG with external APIs or dynamic knowledge graphs for even richer answers.
- Set up automated testing scenarios to validate deterministic behavior and performance under load.
We encourage readers to explore the codebase, try adding their own agents or integrating new retrieval sources, and share their findings. Let’s collectively tackle these challenges—intent modeling, reliable delegation, scalable architectures—and push voice assistants toward a more truly conversational, context-aware future.